Machine Learning on Diabetes Data Sets

Every year thousands of people are diagnosed with diabetes too late, and unfortunately a late, or untreated diagnosis can result in blindness, amputations, heart attacks, strokes, and kidney disease. Our aim was to run machine learning algorithms to the data in order to determine who is most at risk based on commonly known things about each patient. This will allow us to more accurately identify who is at risk, and allow us to catch diagnosis before it is too late.
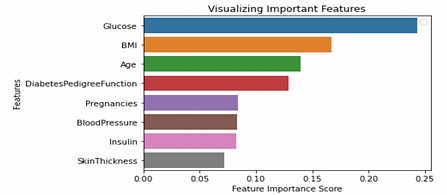
We ran a logistic regression of our data to determine what has the largest correlation with our binary result of having diabetes and not having diabetes. The key results are as follows. glucose and insulin had the smallest standard error, however the probably value, or the likelihood that our results occurred by random chance are demonstrated below
-
Pregnancies (p = 0.000)
-
Glucose (p = 0.000)
-
BMI (p = 0.000)
-
Diabetes Pedigree Function (p = 0.002)
From this data in conjunction with the standard error, we determined that glucose is the ideal key factor in predicting diabetes. We also note that our 95% confidence interval for glucose does not include 0, so our result is statistically significant from zero.
This can be displayed by the correlation on the heat map that we made on the right. If you look at each key influencer compared to the outcome, we can note that glucose has a strong correlation seen on the Heat Map.